
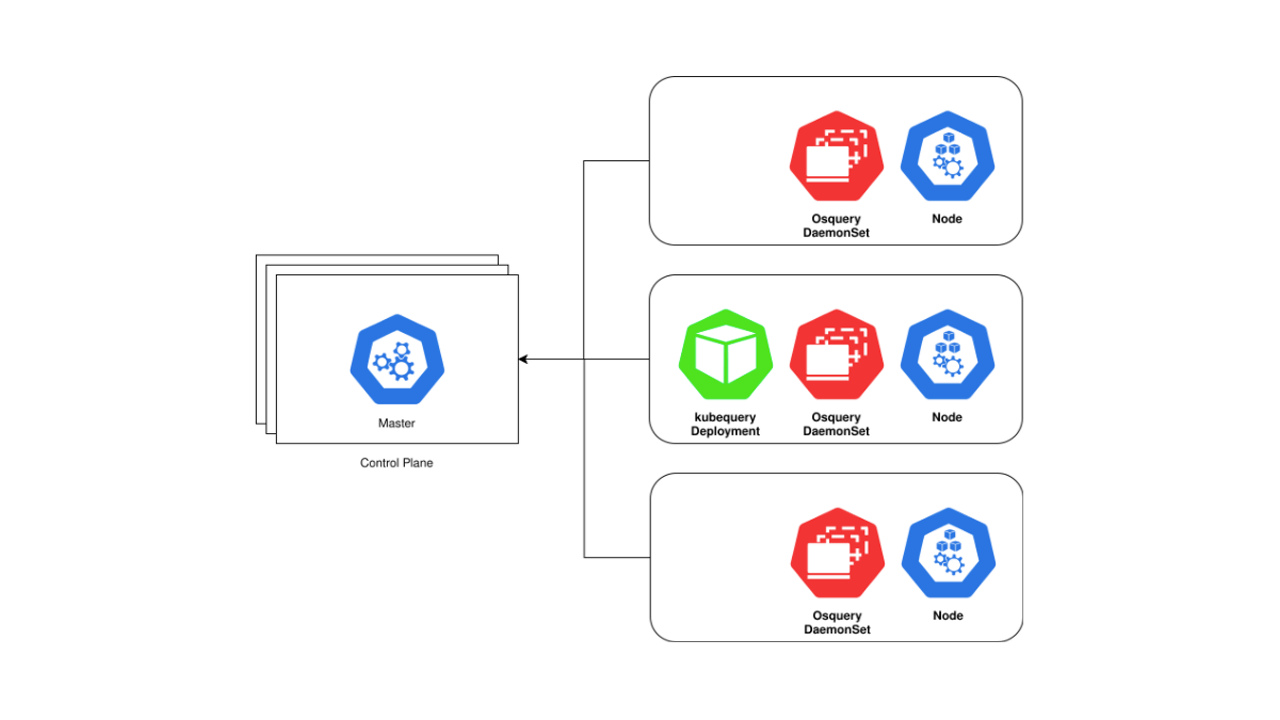
Osquery natively supports containerized workloads and provides visibility into the hosts and the containers running on the host. K8s has opinionated constructs on how the containers should be composed, deployed, and the security policies that control the application workloads.
K8s pod security policies, network policies, roles, bindings, etc. play important roles in securing the K8s cluster. Popular add-ons like Istio also add additional security constructs. There are numerous open source and commercial products that provide visibility and security for K8s clusters.
Kubequery is developed to bring the power of osquery to K8s clusters. All K8s API resources can be queried via SQL. Each resource is modeled as one or more SQL tables. Support for add-ons like Istio will be added shortly. Those familiar with osquery configuration can create scheduled queries and gather information about K8s resources periodically. Osquery’s distributed query functionality can also be used to query cluster resources in real time.
The following osquery configuration will query K8s namespaces, roles, cluster roles, role bindings, cluster role bindings, and pod security policies every 10 minutes. If a remote logger like TLS, Kafka, etc. is configured, the data will be sent to the configured destination(s). It is common to have numerous K8s clusters (dev, staging, production, etc.).
The information available to kubequery helps in providing visibility across all K8s clusters, audit and compliance use cases, and security. For example, you can find out if one or more pod security policies have privileged attributes set to “true,” this could potentially be a configuration mistake and worth investigating. It’s also possible to closely reconstruct the state of a cluster for a point in time in the past, which is useful when analyzing the root cause of a security or operational issue.
{
"schedule": {
"kubernetes_namespaces": {
"query": "SELECT * FROM kubernetes_namespaces",
"interval": 600
},
"kubernetes_role_policy_rules": {
"query": "SELECT * FROM kubernetes_role_policy_rules",
"interval": 600
},
"kubernetes_cluster_role_policy_rules": {
"query": "SELECT * FROM kubernetes_cluster_role_policy_rules",
"interval": 600
},
"kubernetes_cluster_role_binding_subjects": {
"query": "SELECT * FROM kubernetes_cluster_role_binding_subjects",
"interval": 600
},
"kubernetes_pod_security_policies": {
"query": "SELECT uid, cluster_uid, name, privileged, host_pid, host_ipc, host_network, allow_privilege_escalation, value AS 'run_as_user_rule' FROM kubernetes_pod_security_policies, json_tree(kubernetes_pod_security_policies.run_as_user) WHERE key = 'rule'",
"interval": 600
}
}
}
Support
Currently all K8s API resources are supported and kubequery will support all K8s supported versions. All major K8s distributions and SaaS offerings will also be supported. These include: generic Kubernetes, Red Hat OpenShift, AWS EKS, Google Cloud GKE, Azure AKS, etc.
Kubequery deployment
Deploying kubequery is simple:
- Get a recent copy of the kubequery.yaml file from GitHub.
- Update
osquery.flagsin thekubequery-config ConfigMapsection. This is where enroll, config, logger, and other plugins should be configured. Refer to osquery flags for further information. - Update
osquery.confin thekubequery-config ConfigMapsection. This has information about scheduled queries, etc. Refer to the osquery configuration. - Change the pod
hostnameto match the K8s cluster name. - Apply the YAML (e.g:
kubectl apply -f kubequery.yaml).
Kubequery.yaml is a template that creates the following K8s resources:
kubequery Namespace will be the placeholder for all resources that are namespaced.
kubequery-sa is a ServiceAccount that is associated with the kubequery deployment pod specification. The container uses the service account token to authenticate with the K8s API server.
kubequery-clusterrole is a ClusterRole that allows get and list operations on all resources in the following API groups:
- "" (core)
- admissionregistration.K8s.io
- apps
- autoscaling
- batch
- networking.K8s.io
- policy
- rbac.authorization.K8s.io
- storage.K8s.io
kubequery-clusterrolebinding is a ClusterRoleBinding that binds the cluster role with the service account.
kubequery-config is a ConfigMap that will be mounted inside the container as a directory. The contents of this config map should include osquery flags, configuration, etc.
kubequery is the Deployment that creates one replica pod. The container launched as a part of the pod is run as a non-root user.
By default, pod resource requests and limits are set to 500m (half a core) and 200MB. The kubequery.yaml file should be tweaked to suit your needs.

Osquery vs Kubequery
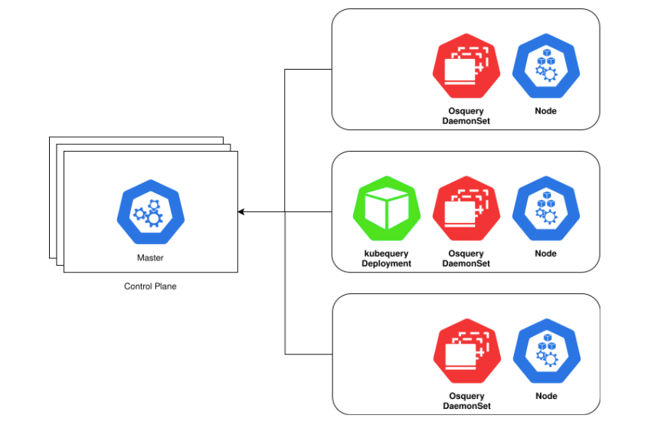
Kubequery compliments osquery. It is not a replacement for osquery. Kubequery is installed as a Deployment, which means there is only one container of kubequery running on one K8s node per cluster. Osquery should be running on every K8s node (control plane and workers).
Currently, kubequery also includes osquery tables like processes, system_info, etc. Querying most osquery tables from an ephemeral pod does not provide much value. Kubequery runs as a non-root user. Many of the osquery tables need root privileges to gather table data, so querying osquery tables might return an error or partial data.
Here’s an example deployment of both osquery and kubequery:
JSON
Normalizing nested JSON data like K8s API responses will create an explosion of tables. Some of the columns in K8s tables are left as JSON. Data is eventually processed by SQLite within osquery. SQLite has good JSON support for extracting and transforming data.
For example, if run_as_user in the kubernetes_pod_security_policies table looks like the following:
{"rule": "MustRunAsNonRoot"}To get the value of rule, the following query can be used:
SELECT value AS 'rule'
FROM kubernetes_pod_security_policies, json_tree(kubernetes_pod_security_policies.run_as_user)
WHERE key = 'rule';Here’s the result:

To explode JSON array types, json_each can be used. For example, if volumes in the kubernetes_pod_security_policies table looks like the following:
{"volumes": ["configMap","emptyDir","projected","secret","downwardAPI"]}To get a separate row for each volume, the following query can be used:
SELECT value
FROM kubernetes_pod_security_policies, json_each(kubernetes_pod_security_policies.volumes);Output will look like the following:

The Future of kubequery
Lots of exciting features are coming for kubequery. PRs are welcome and appreciated. The following are some of the things planned (in no particular order):
- K8s events support
- K8s popular add-ons support (Istio, etc.)
- Remove/disable unnecessary osquery functionality to avoid flags/tables confusion
- Ability to provide
kubernetes_infoduring enroll sequence (instead of asset/endpoint related information)
More to Come
In the following video, Uma Reddy shares Uptycs’ vision for extending the capabilities of osquery to include cloud provider, container orchestrator, and SaaS provider data. These capabilities will let osquery offer inside-out and outside-in monitoring for hosts and containers.



