

osquery@scale is back for the third year running, once again in-person in San Francisco, September 14-15! Two days of technical talks for osquery lovers and n00bs alike. Tickets are on sale now.

The following is adapted from Ryan Mack’s talk “Containers and osquery,” presented at the osquery@scale ‘21. Ryan’s full presentation is available at the end of this piece.
We need as much visibility as possible into everything going on in our containers to effectively detect security problems in container-based environments. We also need to apply the unique properties of containers to create high-fidelity detection rules.
Osquery can meet both of these needs.
A Brief History of Containers
To best manage and secure containers, it’s helpful to understand where they came from.
To start, we go all the way back to 1979 with the introduction of chroot in Unix V7. Chroot was probably the earliest primitive we had for process isolation. The idea being, if you have a process that shouldn’t see the entire file system, you can constrain its worldview to a subdirectory on your server. Anyone who has run web servers, or any kind of Linux server that was connected to the Internet before containers, is familiar with setting up a chroot environment for your process.
UNIX has traditionally had a core metaphor that everything is a file, meaning files as well as devices and control mechanisms all appear in a single logical “namespace.” Plan 9 introduced the idea of multiple namespaces in 1992. This allowed different processes to have different views of the file system and different degrees of access to shared resources. The same idea came to Linux about a decade later. Linux started with only supporting multiple namespaces for the file system. If you look back to the system calls or the parameters to the system calls, they're all just called "new namespace." It wasn’t until later that we started referring to this as the “mount namespace” to differentiate it from other types of namespaces.
Two big changes came to Linux in 2006. The first was cgroups, which is short for “control groups.” This was a way to limit the resources available to a process group. This allowed for you to specify the maximum amounts of CPU, memory, and, then later, even GPU usage to a particular subset of your processes. This also allowed for some level of isolation and fair sharing between different co-tenants on a Unix box.
The introduction of pspaces in 2006 allowed for the addition of multiple process ID spaces on Linux. So when you look at your list of processes inside a container, you might see a different process numbering and a different subset of the processes than if you ran that on your host. After that, additional namespaces were added to support different views of the networking, IPC, and even a different logical root user for the host and inside a namespace.

Figure 1: A history of process isolation.
Will all of these different namespaces, different mount points, and things that we need to configure, LXC, the Linux container project, was our container runtime. It managed the set up and tear down of all of those namespaces in order to constrain your process group inside a running container.
Most of us are familiar with the next inflection point: Docker. Introduced in 2013, Docker leveraged LXC, but instead of just focusing on the life cycle of running your process, it focused on improving the entire development life cycle of your container. Docker allowed you to create reusable image layers so if you wanted to build multiple containers, each container could have shared common components that only had to be built once. Docker also improved and streamlined the distribution of container images, which made container deployment as easy as installing a package on your system. This was one of the most important inflection points in the acceleration of container adoption.
Today, everything is a container. This presentation was developed in Google Slides and the underlying web server powering it was probably running in a container. The video presentation of this talk (embedded at the end of this post) was recorded through a web application, which was likely running in a container.

Osquery & Containers
There are two ways of thinking about containers. The first includes all of the kernel features that we covered earlier: a process group configured with different namespaces, different cgroups, and mounted file system layers in order to configure the environment where your process runs.
We also have a second way of thinking about containers, which is that there's a logical object that lives inside your container runtime. There's an ID that Docker understands to be a container and an ID that Docker understands to be an image. Where this gets complicated is in how these connect to each other.

Figure 2: The complication of containers.
We need tools that are able to reconcile these two ways of thinking about Linux containers. Since I’m presenting this talk at an osquery conference, you're probably guessing my answer is “osquery.” And you're right. Osquery provides comprehensive visibility into things happening inside your containers, in the runtime as well as in the kernel. Osquery exposes SQL tools to allow you to join these concepts literally in your queries.
Let’s look at four categories of tools available inside osquery when working with containers.
Comprehensive Container Runtime Introspection
First up is comprehensive container runtime introspection. This basically means that if there's an API in your container runtime, you can expose that information in a query in osquery.
You can see just looking at the tab completion in osquery that for Docker, Crio, Containerd, and LXD, we pretty much have a table representing anything available in the respective container runtime API (see Figure 3, below).

Figure 3: Comprehensive container runtime introspection in osquery. (Click to see larger version.)
System Tables
The second category includes system tables that have additional columns with information about the container environment that they're running.
In Figure 4 (below) what I'm showing is the ability to apply a shared ID, the process ID namespace, which you can use with a connective query that’s inspecting your process list with information that the container runtime understands about that container. So, we're able to connect up the processes running inside a container to the information about the name of that container coming from the Docker runtime.
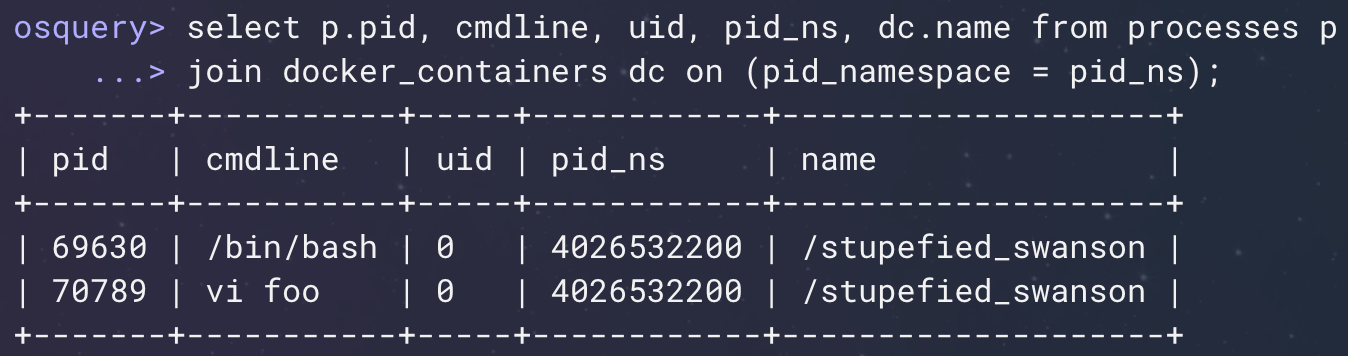
Figure 4: System tables with container-related columns. (Click to see larger version.)
Container Information & Events Tables
The third osquery-container tool category covers events tables with additional container-related information annotated or decorated onto your events.
Of course, not every process is going to get captured if you're periodically polling the processes table. We want to use the eventing image to capture very short-lived processes, as well as file and socket events. Those data sources are now coming from eBPF, which captures enough container information that we can add decorations that allow you to understand the container context where these events are occurring. In Figure 5 (below), I'm first showing you process events where a user is running a VI inside of the container. We're then able to connect that back to the image name and the container name from the container runtime.
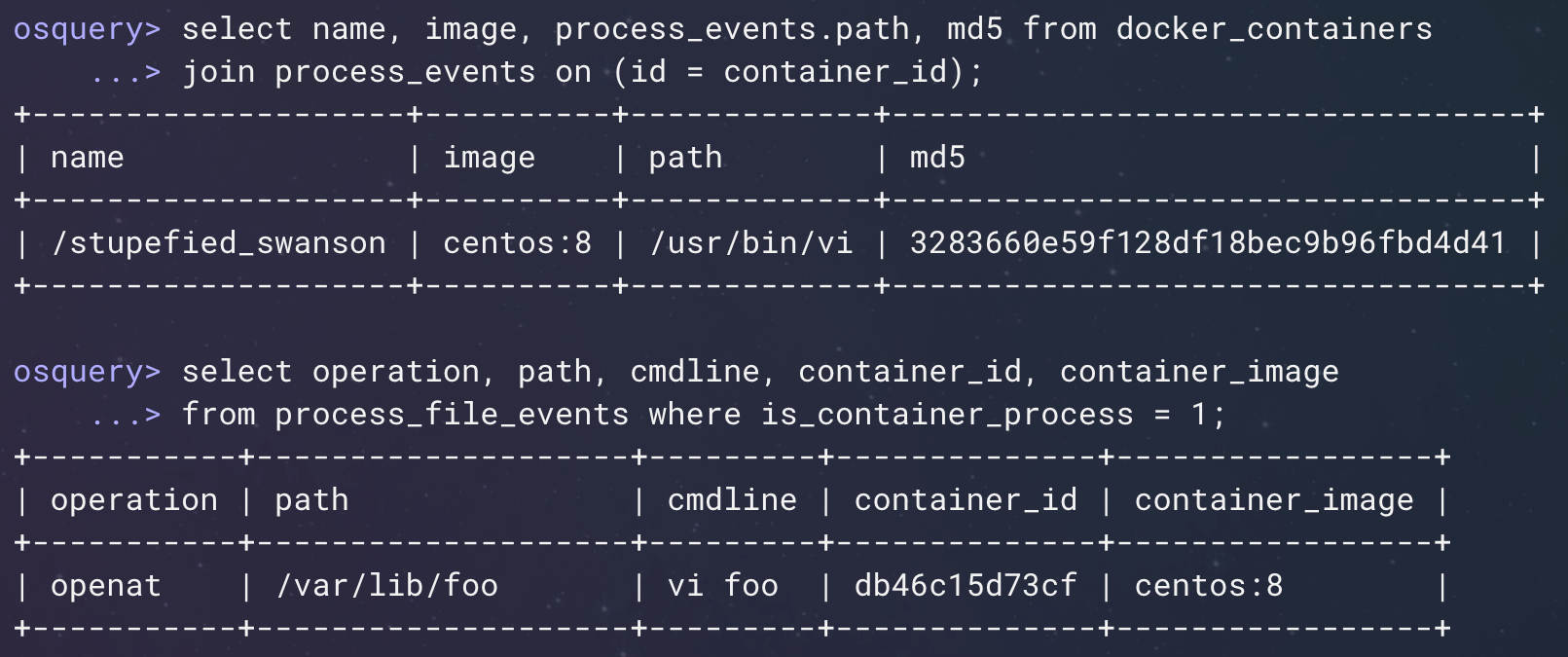
Figure 5: Event tables with container-related decorations. (Click to see larger version.)
Similarly, we're able to detect file modification and connect it back to the container name and the container ID from the runtime. That's going to be very important as we start to build detection rules, where we want to leverage our understanding of what a container should be doing with things that the system is doing that might actually be a security vulnerability.
Container-enabled System Tables
The fourth category we’re going to discuss is "container-enabled" system tables.
The users table in osquery reads from your /etc/passwd file. You have an /etc/passwd file on your host, but most likely you have a different one inside your running containers. Container-enabled system tables allow you to check the contents of the file system within the scope of your running container. In the first example in Figure 6, below, you can see that we are querying the users table for the users that exist only inside one of our running containers.
The second example (the bottom part of Figure 6) is showing a join of the shell_history table with the users table, both from inside that running container. In this case, this is actually showing the commands from the shell history inside the container that was captured in the events in the example above (Figure 5). You can see that I used VI to add a new user inside the container and then started using that user to edit other files inside the container as well.
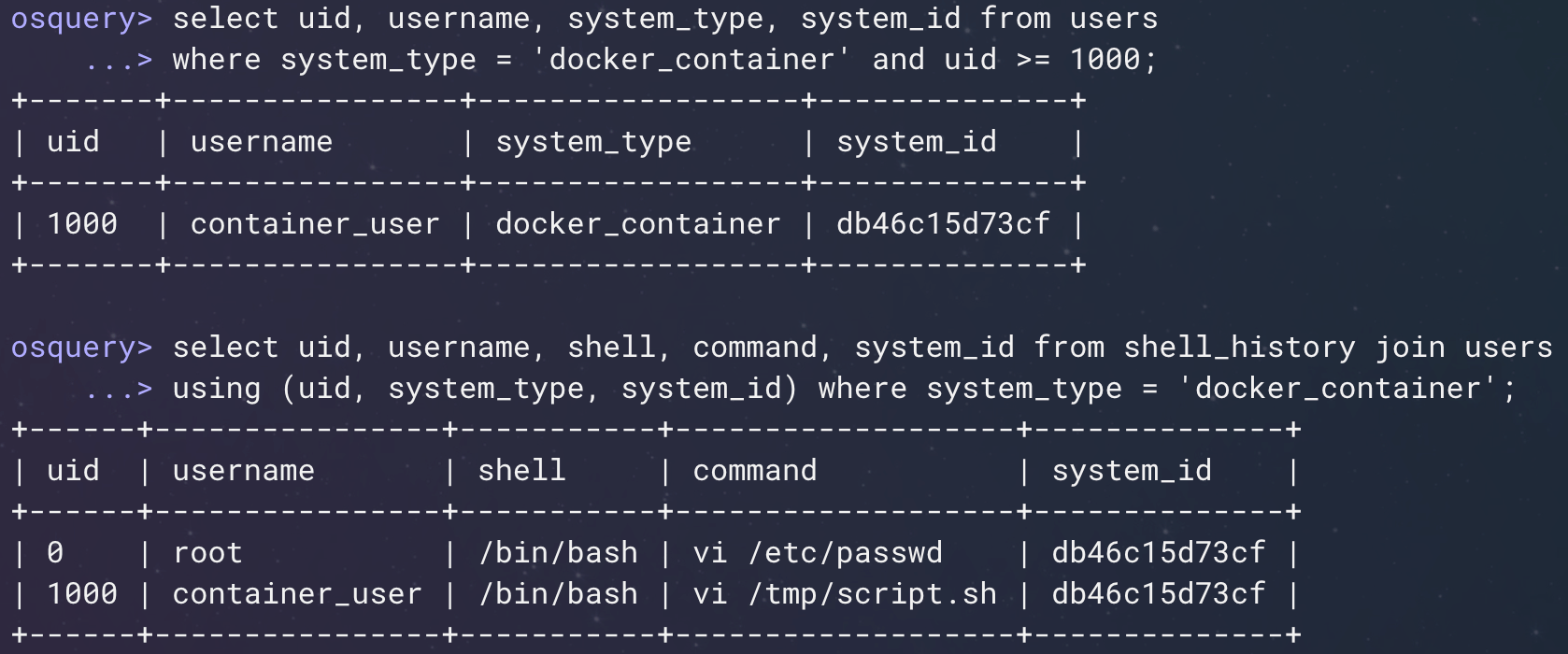
Figure 6: Container-enabled system tables. (Click to see larger version.)
Below you’ll find another example I find useful (Figure 7). You can run your package listings--in this example your Debian package listings--simultaneously on the host and in running containers to extract whatever information you want. In this case, we're doing a quick summary on the number of packages installed on the host and on running containers.
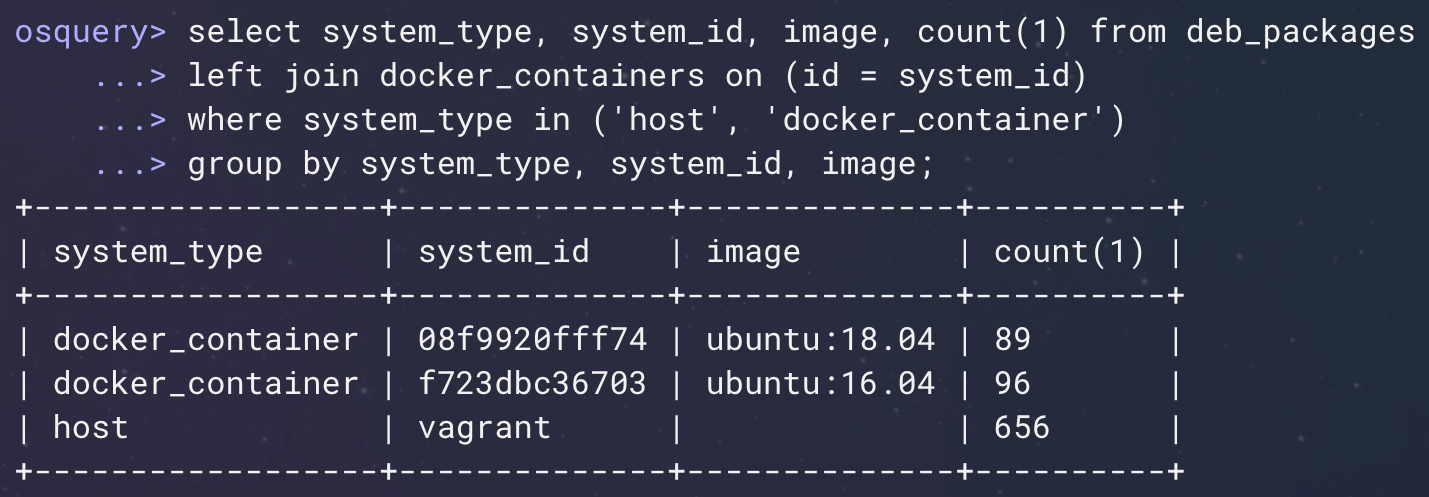
Figure 7: Container-enabled system tables. (Click to see larger version.)
This covers, more or less, the container-related data that’s available to you inside osquery.
Detections: Why are containers special?
There are a couple of important ways detections in containers differ from detections in your host.
First, containers are (intended to be) immutable. In theory, building your software and installing your packages all happens during the steps when you're building a container image. Once the container is deployed and running, typically you aren't going to be installing new software in there.
Second, containers are (usually) single purpose. This isn't always true, but we'd like to see containers where each container is running one service and it generally has a consistent set of other services that it talks to over time.
Third, nobody logs into a container. You deploy your container in production and you aren't debugging inside of a running container on your production system.
Finally, containers have well-defined behavior. When your container is doing something different, you can actually characterize deviations over time.
Now, let's look at examples of how these container properties can be turned into detection rules.
Containers Are Immutable
In Figure 8 (below) you’ll see an example of a detection rule written on processed file events coming out of osquery.
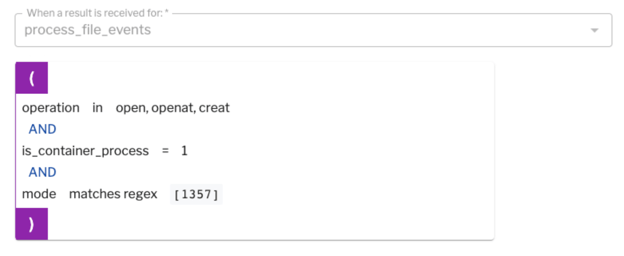
Figure 8: Example of a detection rule written on processed file events coming out of osquery.
If, for example, you see a file is being created inside your container with one of the executable bits set in its file permissions, it's possible someone is introducing a new script or binary inside your running container. That's definitely a signal and it may not be typical for your production environment.
Similarly, you don't normally run “rpm” or “dpkg” in order to install new packages in your container after they're running. In Figure 9 (below), we're looking at a detection rule based on process events when someone runs a package manager inside of your container.
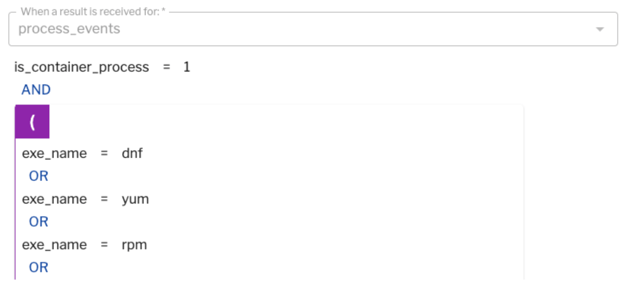
Figure 9: A detection rule based on process events when someone runs a package manager inside of a container.
Figure 10 (below) shows an example of a file rule. If someone modifies a file on disk inside your container in one of your system paths, it’s quite possible that someone is trying to replace one of your standard system binaries with malware.

Figure 10: An example of a file rule.
Containers Are Single Purpose
If you're running Apache httpd and your image name starts with “httpd,” you might be surprised if there are other processes running inside that container. In Figure 11 (below) we've written the detection rule based on process events, or the httpd container, if it starts to see executables with different names. Your container deployment might be different, but this lets you think about the fact that for a given container image, you can start to characterize the processes that you expect to see in them and provide a high signal when something abnormal is happening.
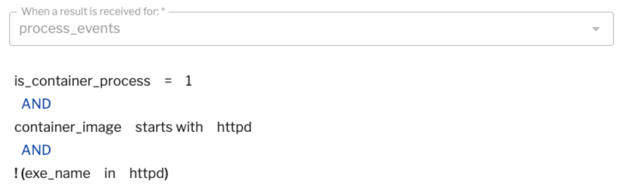
Figure 11: A detection rule based on process events.
If your application only communicates over TCP, the following is an example of an event rule on the socket_events table (see Figure 12, below). If you detect an outgoing connection over UDP, excluding DNS, that's an indication that someone might be communicating to a command-and-control server from software running inside of your container.

Figure 12: An event rule on the socket_events table.
Nobody Logs Into a Container
Figure 13 (below) shows an example of “nobody logs into a container.” Again, here we're detecting process events. If any process is invoked with its parent process being SSHD, or if you are detecting any login processes inside your container, you probably are detecting someone who's figured out how to log into your container. This is a useful signal in a container environment.
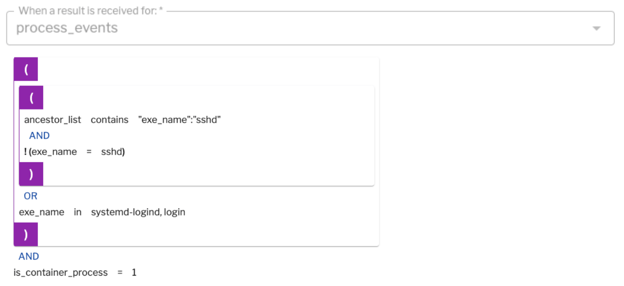
Figure 13: Detecting process events.
Containers Have Well-defined Behavior
All of our applications are going to be different and as you deploy any sort of detection rules, you will over time determine the things that are showing up as noise in your alerts. Figure 14 (below) is an example of this. As you characterize your container's behavior, you can slowly build up rule sets to reduce the noise and ensure all of your alerts are high signal.

Figure 14: You can build up rule sets to reduce noise and ensure your alerts are high signal.
Of course, the combination of multiple events is a good indicator that you've been compromised. Figure 15 (below) is a screen grab from one of our tools where you can build a detection of correlation across multiple events.
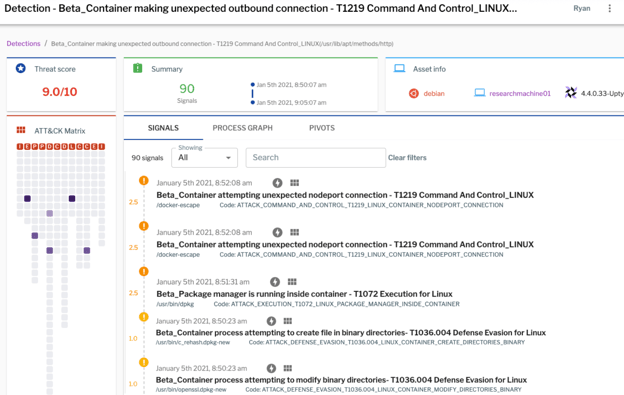
Figure 15: You can build a detection that correlates across multiple events.
In this example you’re seeing multiple process events, network events, and file operations, all of which suggest there's a good chance something bad is happening. In this case we've seen 90 such signals within a 15-minute window. That's a very high indication someone breached one of your containers (this screen grab shows a capture of detonating a malware example in one of our research environments).
So, that's how you can build detection rules and use them in a container environment to give you high-signal detections.
Closing Thoughts
I see the future of containers and container security evolving in three directions.
More Abstract
Everything we've talked about here is focused on a host, a kernel, and a container runtime environment. Going forward, a lot more of this will be managed for you by container orchestration frameworks. Because of this, we’ll need to think about how we incorporate information coming from Kubernetes or a cloud provider into analysis and detection rules.
In addition, abstraction means we're not necessarily deploying hosts or node groups anymore. Now, we're working with things like AWS Fargate, where we're deploying containers and allowing the cloud provider to figure out how to map that onto actual virtual machines.
We also have to think about building detection rules and detection environments inside host-free environments. If you take this to the extreme, we're starting to think about how we handle AWS Lambda, where you're not necessarily running services anymore—you might write a function and leave it to Amazon to manage the full life cycle.
More Secure
We’re evolving toward more secure container environments. Amazon Fargate runs on a modified hypervisor that is much more secure, but it eliminates a lot of the approaches that we're currently using for process inspection. For example, you can't run eBPF or Audit inside of a container running inside Amazon Fargate. Similarly, Google has introduced gVisor, which offers an interesting user-space layer between an application and the kernel that provides additional security, but also limits visibility. This area represents a continued direction for research.
More Intelligent
Container security will become smarter. Everything I've talked about here focuses on how you can build detection rules for your containers based on your understanding of the expected workloads. Going forward, machine learning will become an increasingly powerful tool for understanding the baseline behaviors of your container application. Because containers are generally single purpose, it's easier to build well-trained machine learning models based on normal and anomalous behavior for your containers.
As someone who built my first Linux FTP servers using floppy disks, the evolution to running each application with its own self-contained system image, and those running on a set of Kubernetes-managed virtual machines, has been somewhat mind bending. All the time saved by simplifying the bring-up and deployment process has, to some degree, been at the cost of additional monitoring complexity. I’m happy to be playing a part in the evolution of osquery so that it can remain a best-in-class security solution even amid such foundational shifts in the way we build and deploy our applications.
Schedule a demo to learn about the container security functionality in Uptycs.
Full Presentation
Check out Ryan’s “Containers and osquery” talk in the following video:




