


According to the official osquery docs, osquery (os=operating system) is an operating system instrumentation framework that exposes an operating system as a high-performance relational database. Using SQL, you can write a single query to explore any given data, regardless of operating system (more on osquery basics here).
This, fundamentally, can help you see why osquery is a handy utility right out of the box, but the real value of the instrumentation agent is discovered when the data it can access is gathered and analyzed with osquery at scale, across an entire enterprise.
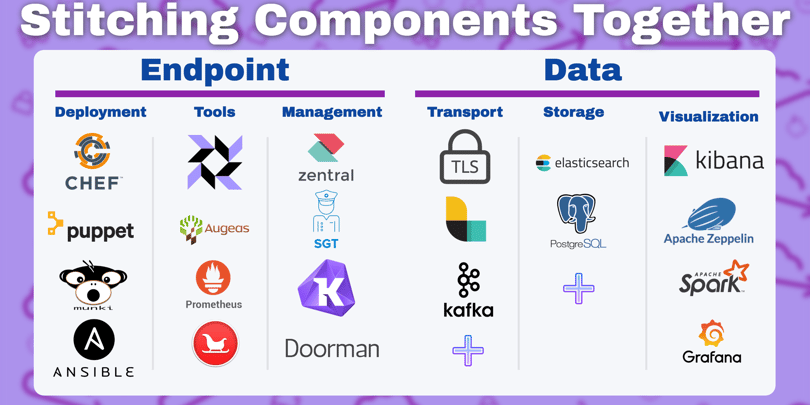
When you look at developing a solution like this, osquery is a key part, but the entire system is not possible without additional components handling the transport, aggregation, storage, and presentation of all the rich data that osquery can provide.
In some cases this could mean introducing a commercial offering, but in this post we’re going to outline how to make osquery work using supplementary open-source tools.
This list is by no means exhaustive, but we’ve distilled it down to some of the most commonly used tools for building an osquery ecosystem. We’ve split them into six respective functions:
- Endpoint configuration
- Endpoint inspection
- Endpoint management
- Data transport
- Data storage, and
- Data visualization
Combining one tool from each of these functional areas will be a Do-It-Yourself starting point for deploying osquery at scale.
Key Takeaways
-
Osquery at scale requires more than the agent itself. Effective deployments depend on a supporting ecosystem for endpoint management, data transport, storage, and visualization.
-
Open source tools can cover the full osquery lifecycle. With the right combination of configuration, fleet management, and analytics tools, teams can build a flexible and scalable osquery environment.
-
Designing for scale upfront enables long-term value. Planning for data volume, transport reliability, and historical analysis is critical to getting sustained insight from osquery across large environments.
How Do You Deploy Osquery at Scale Across Endpoints?
How will you efficiently and seamlessly deliver osquery to the endpoint when running osquery at scale?
Chef, Ansible, and Puppet: while each of these tools have their own strengths, they all serve to allow you to automate provisioning and configuration of endpoints for a variety of operating systems, and can be used to push osquery packages and configurations out to endpoints at scale.
Munki: The outlier of the group, Munki is specific to macOS fleets. It allows for configuration and update of software packages on macOS, and can be used to deploy osquery.
Which Open Source Tools Enhance Osquery Inspection?
What tools will you be inspecting the endpoint to get data with?
We are building this potential solution set around osquery, so we will assume that osquery is the primary tool used to inspect the endpoint. However, there are several open-source tools that osquery integrates with or is packaged with that bear mentioning, and many more that can be integrated or used in complement with osquery via extensions.
Augeas: Commonly used to read configuration files into key-value pairs; this tool is built into osquery to make *nix config files parse-able by osquery. Osquery wasn't originally designed to read files but a lot of linux config settings are stored in text files, and this allows all of the supported types in Augeas to be addressed as key-value pairs in a table, without having to write code for an additional osquery table for each one.
Prometheus: An open source metrics collection & publishing project that was initially birthed by the security team at SoundCloud. If you combine osquery and Prometheus, you can query a Prometheus API and get high fidelity performance counter results inside of osquery, something which current osquery is somewhat lacking in. Although some find there is a bit of a learning curve, its flexibility and efficiency make it worthwhile.
Google Santa: unrelated to the other Google Santa project that tracks Kris Kringle’s journey. As he typically does, Santa determines whether things are naughty or nice. In this case, we’re gauging binaries on macOS. This tool can determine what is running on your machine and potentially prevent the spread of damaging binaries across your fleet through white or blacklisting what files are allowed to execute on your Macs. With a recent extension for osquery created by Trail of Bits, Google Santa can now be managed from osquery.
How Do You Manage an Osquery Fleet at Scale?
How will you manage your fleet of hosts running osquery?
For our use case, Endpoint Management for osquery ideally means allowing you to issue commands across all of your machines rather than just one at a time. This can be done by changing scheduled query packs, but can in many cases also allow you to run queries on an ad-hoc basis. All of the tools for this step listed here include a TLS server, but you could do this through configuration changes and log-shipping.
Doorman: One of the initial osquery fleet managers. Appreciated amongst users but discussed less frequently given the availability of newer endpoint management tools with more features.
Fleet: Another Golang powered fleet manager, Fleet was first a commercial product from Kolide that was then released as open-source. Fleet is still a core component of Kolide’s commercial offering, which has expanded beyond what is in the Fleet component.
Zentral: Zentral is a greater framework for capturing events from a variety of sources and linking them to an inventory. It uses osquery among other technologies, and also works with Google Santa (independent of osquery). Built on Python, Zentral identifies as a best fit for emerging to medium-sized IT teams, and has a slightly different structure in terms of how they treat osquery endpoints versus TLS servers purpose-built for just managing osquery.
SGT: The most recent addition to this list, released in early 2018, is an osquery server that was built by the team at Okta using Golang (hence its namesake, Simple Golang TLS).
How Is Osquery Data Transported at Scale?
How will you get the data from one point of your system to another?
The whole point of an osquery management system is to gather data and put that data somewhere you can use it when operating osquery at scale. There are two main points where data is transferred. From the endpoint to the management solution, and then from the management solution to the data store. There are many, many ways to do this, but several pop up more regularly than others when running osquery at scale:
TLS Server: The most common way to get data off an osquery endpoint to a central management system is by using a TLS server. Some of the same technology that allows your web browser to talk to a website securely is built into osquery, and osquery endpoints will happily talk to a TLS application server if both sides are correctly configured. This is what most osquery at scale solutions are built around for endpoint-to-management data transfer.
Beats and Logstash: Created for use with Elasticsearch, Beats endpoints and Logstash servers are used for shipping logs from endpoints and then processing and writing the data into storage, usually as a part of the popular ELK stack method of ingesting, processing, and parsing data. Some of the first implementations of osquery were using ELK. This covers transporting data from the endpoint to the management cluster, and then also along to the backend data store.
Kafka: A databus tool that moves data from the management server to a variety of backend data stores and processing systems. The bus metaphor is invoked because the data travels along a route that may include several “stops” and/or processing along the way. It is not just being moved from one destination to another. If implemented properly, Kafka allows for much more efficient use and analysis of data, and also allows data to be written and stored in different systems that can run in parallel and provide different types of functionality.
Where Should You Store Osquery Data at Scale?
Once you have the data, where and how will you store it?
Data storage can be any sort of relational SQL or unstructured database that can handle osquery data. There really is no limit to what you can use here. However, it should be a technology that you are familiar with, and can plan for the eventual need to scale if you are going to keep osquery data long term.
One of the core benefits of thorough data storage is the ability to execute historical incident investigation. The most popular solutions include:
Elasticsearch: An unstructured key-value pairtype database. This was the initial means of storage used by Facebook. It is more robust in some ways for dealing with large amounts of data than a normal relational database. Elasticsearch allows for horizontal scale and is designed for users to get more out of unstructured data. Part of the ELK stack.
Postgres: A very common relational database that has become the de facto standard for open-source SQL in many organizations.
How Do You Visualize Osquery Data at Scale?
How do you see what matters in the data that you have collected?
Once you have all this rich endpoint data from osquery, what do you do with it? Data visualization is important to both understand the scope of what osquery can provide, to see trends that can be derived from osquery data, and also to attempt to look through this data for anomalies and information to support incident investigations or hunting. Without being able to make sense of the data, even very rich data is useless.
The solutions here are some of the open source options available, but many organizations will end up eventually building their own customization using these, and/or some combination of their existing visualization solutions.
Kibana: The most commonly used open-source data visualization tool for osquery builds. Part of the ELK stack, a natural fit for teams already using Logstash and Elasticsearch. Kibana has a domain-specific language that allows you to write a variety of queries that cut down on the data displayed, segregate what matters for a given use case, and allows for rough pivots on some types of data.
Grafana: More suited for trending data over time. Another package that allows you to build visualizations off of queries derived from a data store.
Apache Zeppelin and Spark: Analysis notebooks that allow you to create queries in a graphical notebook format. This allows for metadata and formatting to be placed around the data output, and in many cases, the queries can be exported in a portable format, with or without the data, to share with others. These tools are not as easy to use for time-based queries as Kibana, but they allow more ways to approach the data for analysis.
Don’t forget, successful deployment requires people plus process plus technology. While we’ve provided suggestions about the open source technology you can use to deploy osquery at scale, you will still have to determine which align best with your organization's inclinations, existing processes, and resources. In many cases, the path of least resistance is to use whatever your administrators already have in place and build on top of that, or adopt tools that fit your technical team's talents and skill sets.
Related osquery resources:
Frequently Asked Questions (FAQ)
What does “osquery at scale” mean?
Osquery at scale refers to deploying, managing, and analyzing osquery data across large numbers of endpoints, often thousands or more, while maintaining performance, reliability, and centralized visibility.
Do I need a fleet manager to run osquery at scale?
While it is technically possible to manage osquery through configuration and log shipping alone, most large deployments rely on an osquery fleet manager to simplify endpoint management, scheduling, and remote querying.
Which open source tools are commonly used with osquery?
Common tools include configuration managers like Chef or Ansible, fleet managers such as Fleet or Zentral, transport systems like TLS servers or Kafka, storage platforms such as Elasticsearch or Postgres, and visualization tools like Kibana or Grafana.
How is osquery data typically transported and stored?
Data is usually sent from endpoints to a management layer using TLS, then forwarded to backend systems using tools like Logstash or Kafka. Storage can be handled by relational databases or unstructured data stores, depending on scale and use case.
Can osquery data be used for historical investigations?
Yes. When stored properly, osquery data enables historical analysis, incident investigation, and threat hunting by allowing teams to query past system states and events.
Is an open source osquery deployment suitable for enterprise environments?
Open source tools can support enterprise-scale osquery deployments, but success depends on proper architecture, operational expertise, and ongoing maintenance to ensure reliability and performance.



