Mastering Kubernetes Security #3: Runtime Admission Controls
Kubernetes is quickly becoming one of the most popular platforms for developing and deploying applications. However, simplifying application deployment can open up numerous security risks unless you take protective measures to secure your Kubernetes environment.
Let’s focus on Runtime Admission Controls (RACs). RACs add a layer of protection that ensures compliance and verification after the admission controller has approved an object. By implementing appropriate rules and processes with runtime admission controls, your organization can ensure protection from any malicious or improper code execution.
Benefits of Admission Control
SecOps Teams want to ensure that insecure resources, be it a pod, container, or even an ingress controller, are deployed with secure defaults. Insecure and non-compliant resources or resources with insecure defaults should be blocked from deployment. At the same time, developers want to move fast and not be overly restricted when it comes to deploying simple applications, especially in dev-test environments.
The concept of admission control was created to enforce runtime policies. Admission controllers in a cluster provide the ability to set policies that can enable secure guardrails for deployments of Kubernetes objects, be it a cluster role binding, workload, namespace, and more. At the time of resource deployment, the Kubernetes API intercepts the request and validates it against a set of policies deployed on the cluster. If the policy is not passed, the object deployment will fail. These policies can be tailored to meet business needs and set secure defaults. For example, you can write policies around:
- Privileged pods: Kubernetes provides Pod Security Admission policies to be able to prevent insecure workloads such as privileged pods from being deployed. Privileged pods, if exploited, can lead to container breakout, which can lead to the exploitation of an entire host.
- Namespace resource limits: Each developer or business unit typically gets its own namespace in shared cluster setups. However, when these namespaces lack predefined resource limits, it often leads to competition for resources, causing issues for customers. This can lead to a security issue as an attacker can deploy and inflate a namespace to a point with a large application that can kick out other mission-critical applications on a cluster. Admission policies can check for default resource limits defined on a namespace manifest and fail namespace deployments that don’t have limits and/or quotas defined.
- Insecure ingress controller: Network security is a key challenge in Kubernetes from a dev/test point of view. To test if things actually work, developers deploy an nginx or kong ingress controller that allows any traffic specified using a wildcard hostname. This is especially seen given the number of IaC examples that exist today. However, this can lead to public internet exposure in production environments, a crucial security risk as any malicious unauthorized user can access the cluster. Admission policies can be written to check for specific hostname strings such as */wildcard and block appropriately.
Several open-source solutions are available to implement admission control, including OPA Gatekeeper (which employs Rego for policy definition) and Kyverno. Additionally, Kubernetes offers built-in features like Pod Security Admission and Pod Security Standards to address critical concerns, such as preventing privilege escalations. However, some key challenges occur today when using admission controls. Let’s take a look at those challenges.
Key challenges with admission control
- Breaking production: While there are many ways to do admission control today, DevOps teams in many situations are hamstrung in enforcing admission control in production environments because it can break production applications if an incorrect policy prevents an object from being blocked. In those situations, developers may not be well equipped to understand the consequences of violating those policies, especially if those policies are primarily configured only by SecOps teams. Solutions, such as OPA Gatekeeper, can do dry runs or audits rather than enforcement to understand what policies would break without preventing actual deployment.
- Lack of integration with DevSecOps tooling: While customers may have tooling for CI or registry scanning for vulnerabilities, malware, and secrets, most admission controllers today don’t look at the data that comes from the scanning results to make an informed decision on whether to allow or prevent a container image from being used for container deployment. The siloed decision-making process results in additional time spent correlating data and cautiously managing basic runtime deployments.
- Increased cognitive load for developers: Policy controls, much like vulnerability management, are essential. However, developers need to easily identify the most relevant policy failures. Simple developer-friendly tooling that allows engineers to triage what audit failures are most relevant to their specific namespaces and pods in a single UI is key to allowing developers to remediate issues faster.
- Inconsistent policy enforcement across cluster fleet: Management of policies at cluster fleet-level scale can be an extreme challenge, especially when there is a lack of visibility in which policies are applied where and duplication. Customers need single-pane-of-glass visibility to see which policies are enforced and to categorize the most important issues across different types of Kubernetes resources so the appropriate engineers get visibility into what is most relevant for their work.
- Aligning/deciding criteria for admission: Deciding the right balance of controls between SecOps and engineering can be a big challenge and requires consistent communication as new requirements come in. At the same time, how do you decide what to enforce, especially to strive for consistency? The indicators of compromise or default secure configurations must be broad enough to support all your different environments.
Enforcing admission controls using Uptycs
Uptycs solves the key challenges outlined above by offering native admission control for the following:
Image deployments: Uptycs can integrate directly with registry scanning to block images with critical or high vulnerabilities found in a registry scan from being used for container deployments on a cluster. This allows SecOps teams to be confident to shift left and catch security issues earlier in the software development lifecycle (SDLC) while enabling those same guardrails using valuable information from the registry scan result for runtime deployments.
In the example below, we see image failures for the Zookeeper image because 42 critical and high vulnerabilities were found.
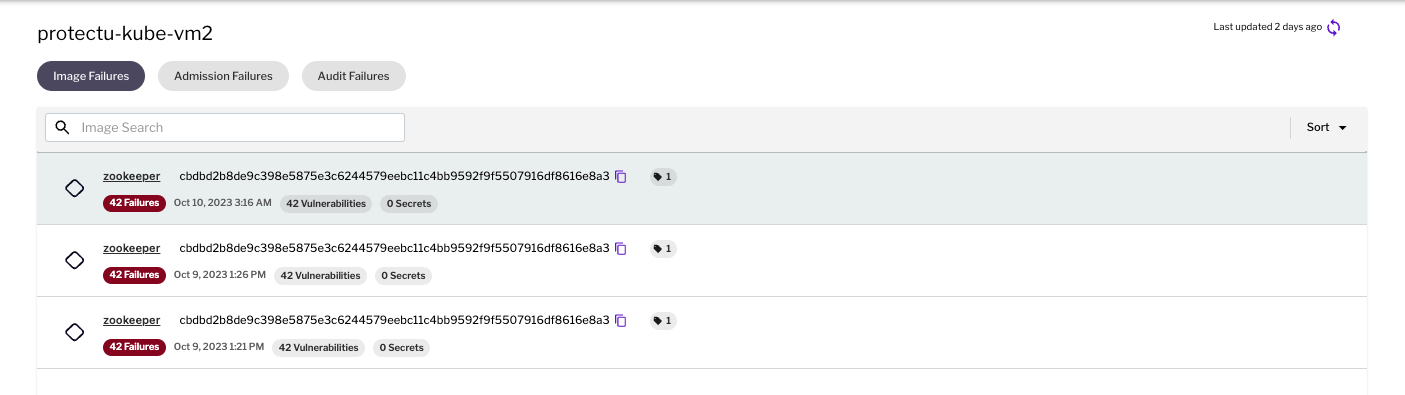 Figure 1 - Image admission failures
Figure 1 - Image admission failures
Runtime deployments: Uptycs integrates with OPA Gatekeeper and acts as an actual admission controller for OPA Gatekeeper so that you don’t have to deploy it separately. Customers can create their own OPA Gatekeeper policies based on business needs or use some of the turnkey policies that Uptycs provides. With these policies stored in Git, customers can use GitOps to push the policies to their cluster fleet and gain single-pane-of-glass visibility at both the policy and individual asset levels.
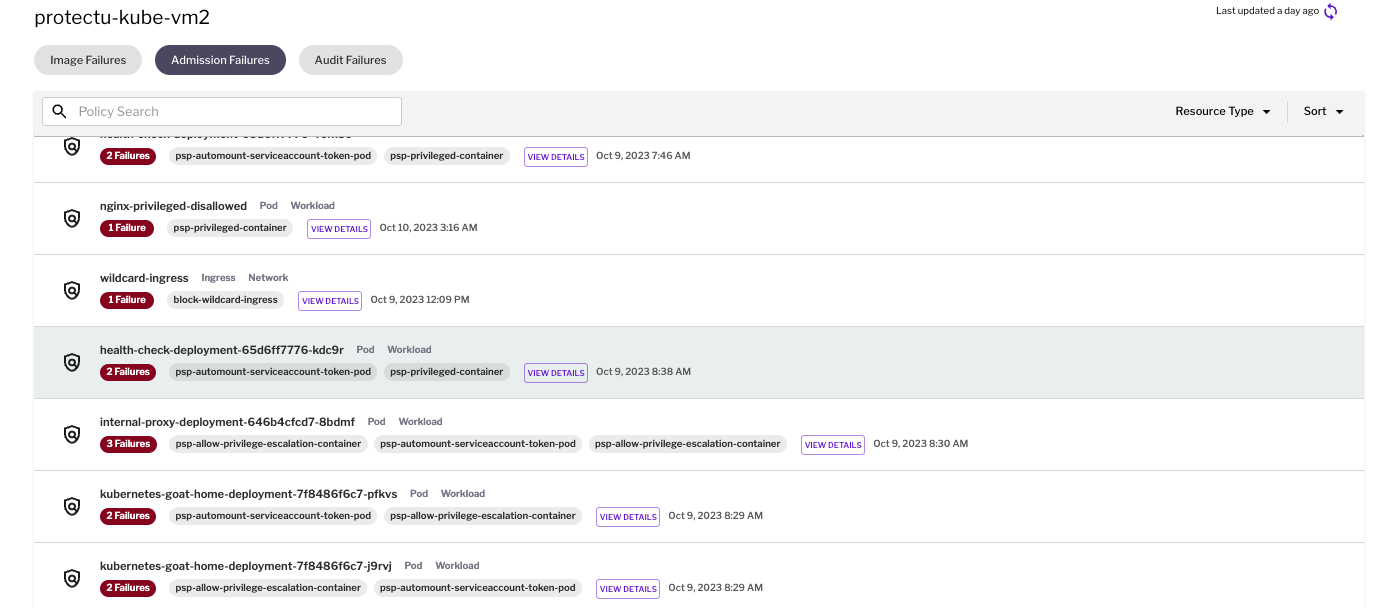
Figure 2 - Runtime Policy admission failures
As seen above, at the policy level, SecOps teams get a single-pane-of-glass view of their admission failures (i.e., which resources failed deployment and against which policies), as well as audits (i.e., which policies are being violated the most for existing resources that are already deployed).
In the example below, we see a wildcard ingress controller that has failed deployment because it is using a wildcard host, which can be used to intercept traffic from other applications and allow any malicious attacker on the Internet to enter the cluster.
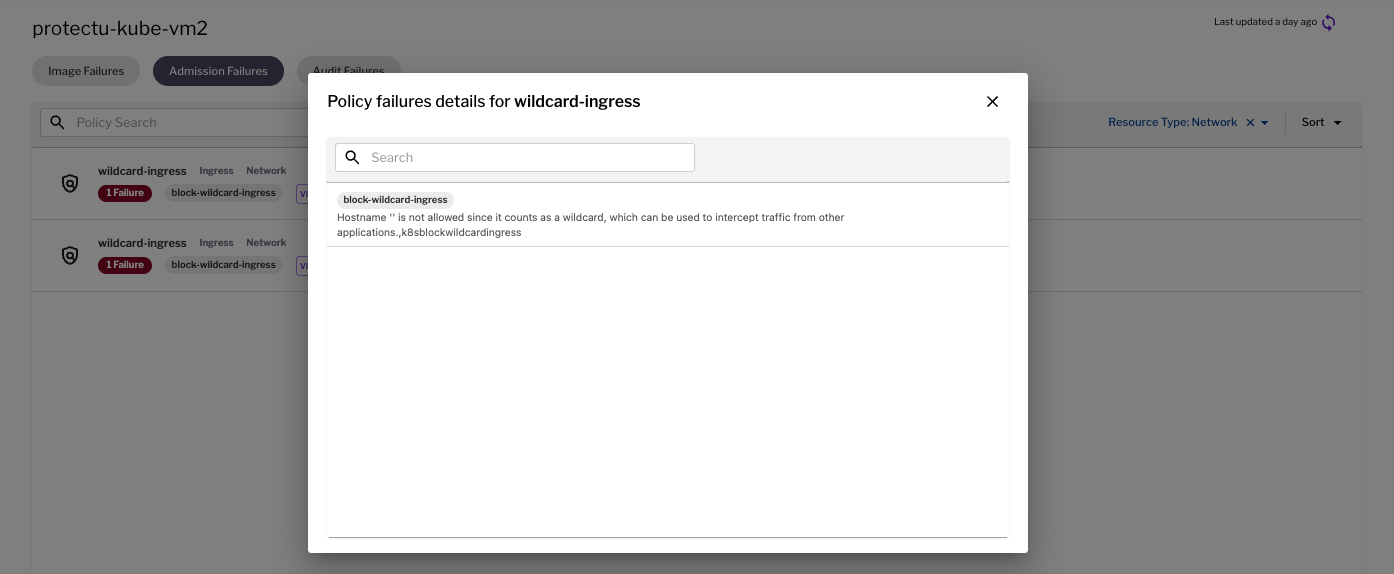 Figure 3 - Example admission failure for ingress controller
Figure 3 - Example admission failure for ingress controller
Similarly, from a DevSecOps point of view, developers can look at audit failures for the specific namespaces they have access to rather than having to cut through all the noise across all the policies. This allows them to easily prioritize and reduce the cognitive load in understanding which policies they need to fix for their specific applications.
The example below shows that the nginxns namespace has one audit failure. The DevOps or developer engineer responsible for that namespace can click the audit failure to see what failed.
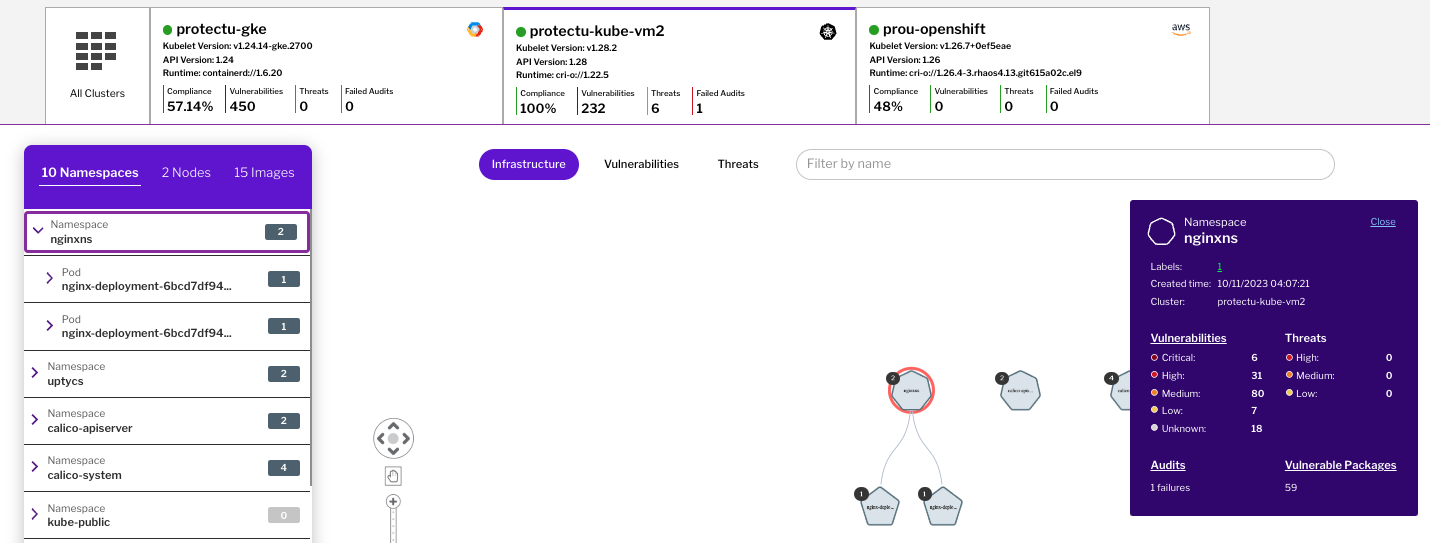 Figure 4 - Audit visibility at the namespace level
Figure 4 - Audit visibility at the namespace level
These controls can easily be enabled as part of the Uptycs protect capabilities during onboarding or via a simple helm update!
In Closing
As Kubernetes ecosystems continue to grow and evolve, ensuring secure defaults and robust hardening measures become paramount. Admission controls play a pivotal role in this security landscape, balancing developers' agility and the imperative for stringent security protocols.
While challenges exist, solutions like Uptycs offer a holistic approach to seamlessly integrate security throughout the development lifecycle. By harnessing the power of admission controls and integrating them with other security facets, organizations can fortify their Kubernetes deployments against potential misconfigurations and threats. As we journey ahead, embracing these tools and strategies will be key to building a resilient and efficient Kubernetes environment.
Stay tuned for our next blog in this series, where we’ll discuss key threat indicators for Kubernetes in Uptycs based on Kubernetes GOAT.








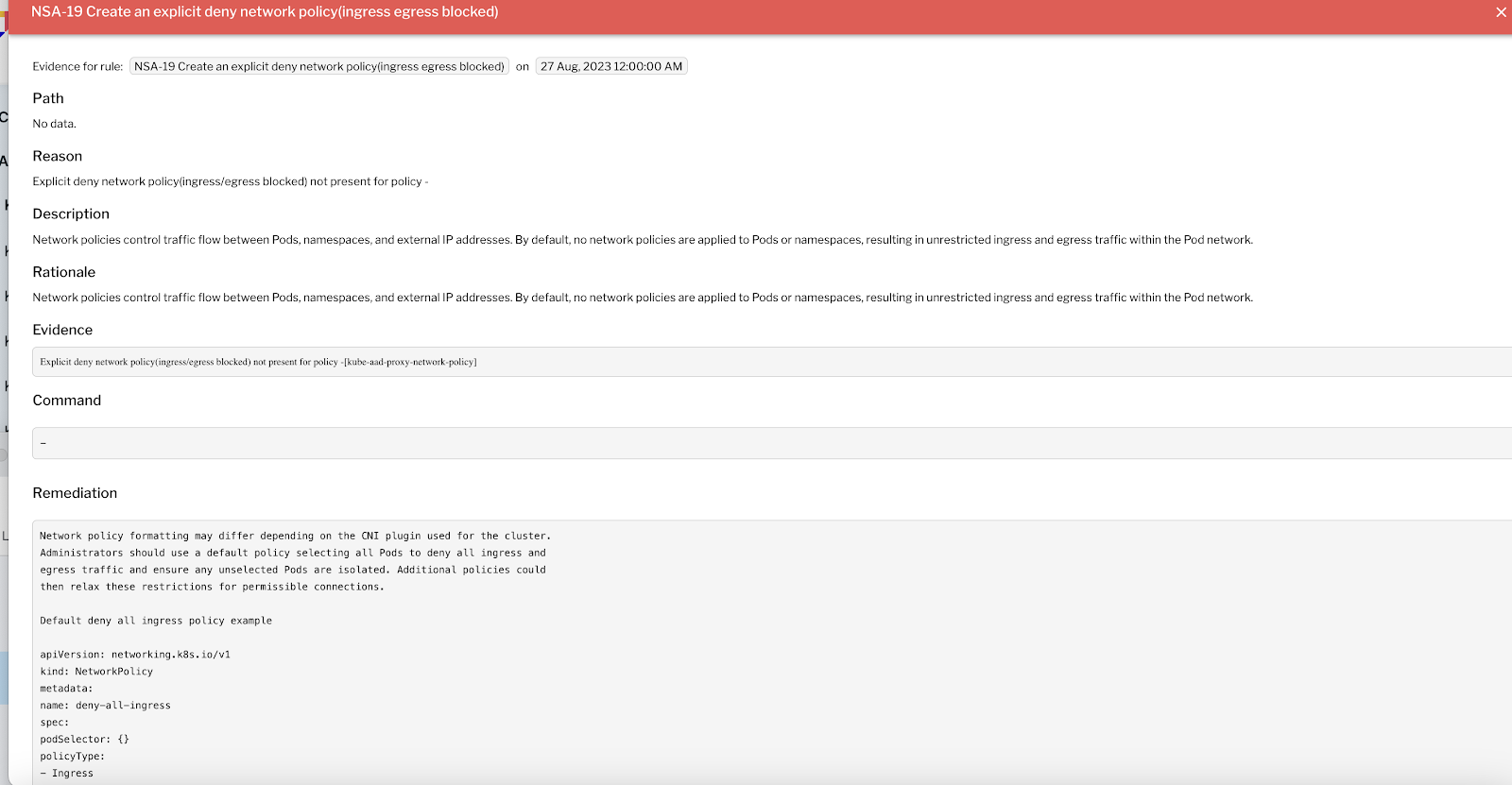 Figure 5 - Network policy evidence
Figure 5 - Network policy evidence
.png)
 Figure 1 – Container vulnerabilities dashboard in the Uptycs platform
Figure 1 – Container vulnerabilities dashboard in the Uptycs platform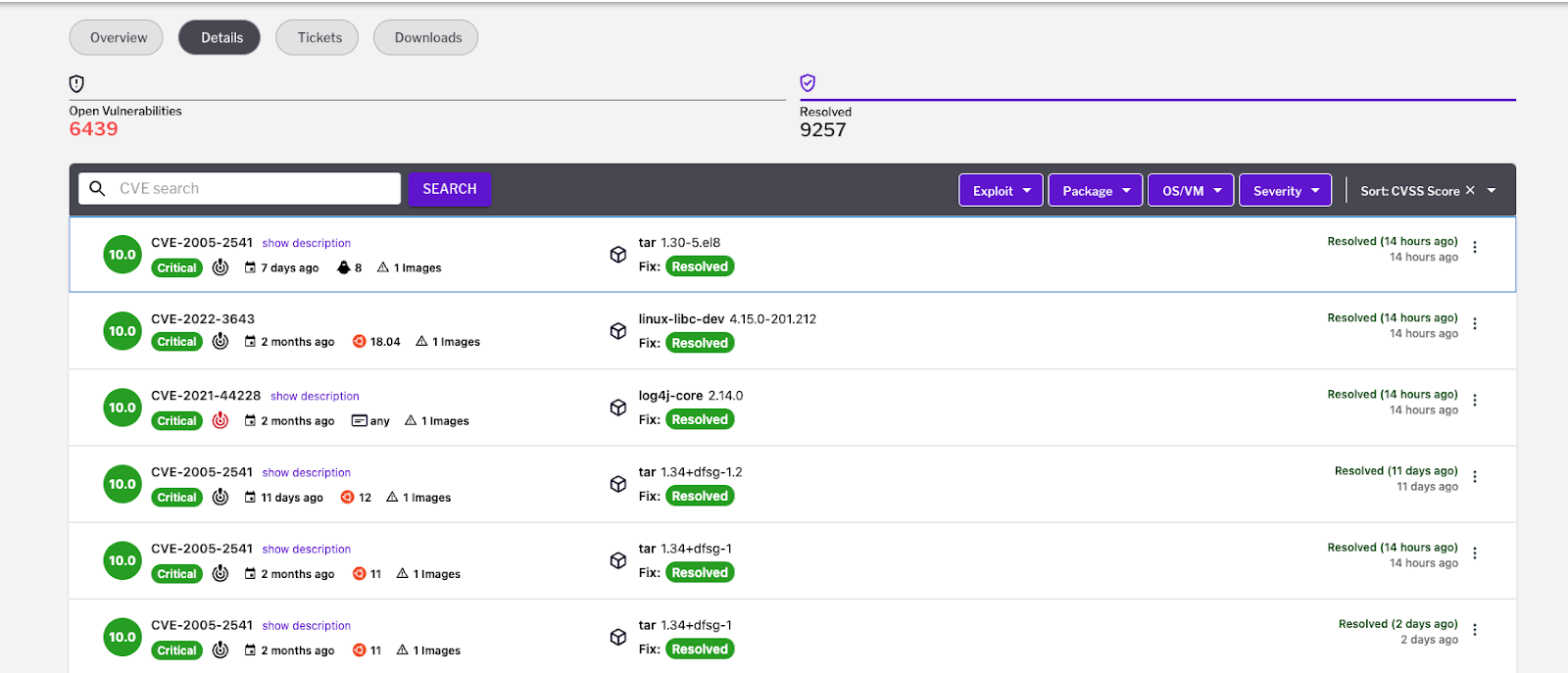 Figure 2 – Resolved vulnerabilities shown in the Uptycs platform
Figure 2 – Resolved vulnerabilities shown in the Uptycs platform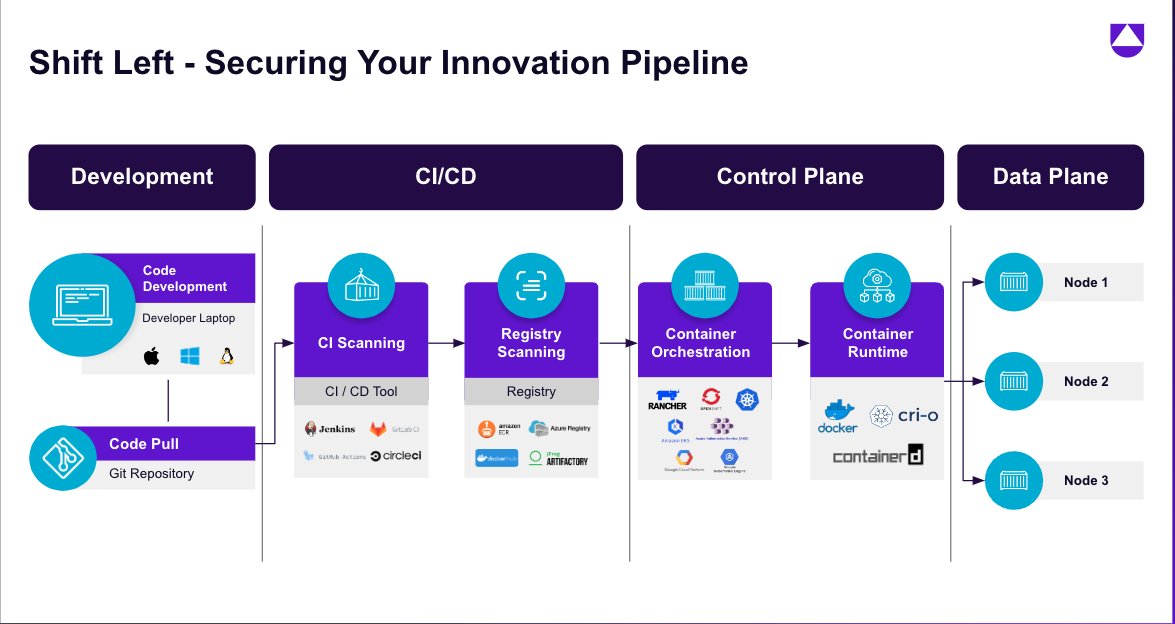 Figure 3 - Secure your innovation pipeline from code to cloud
Figure 3 - Secure your innovation pipeline from code to cloud Figure 4 – CI Image scanning in the Uptycs platform
Figure 4 – CI Image scanning in the Uptycs platform Figure 5 – Registry scanning in the Uptycs platform
Figure 5 – Registry scanning in the Uptycs platform Figure 6 – Image traceability through the SDLC
Figure 6 – Image traceability through the SDLC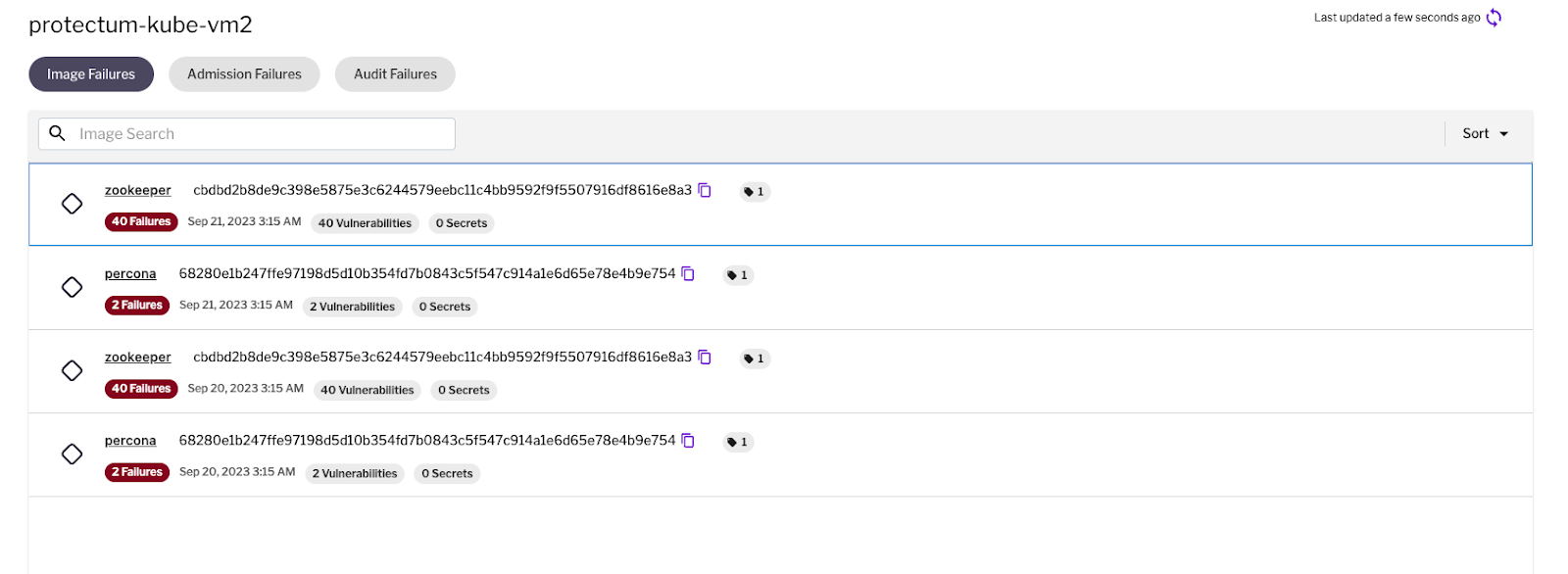




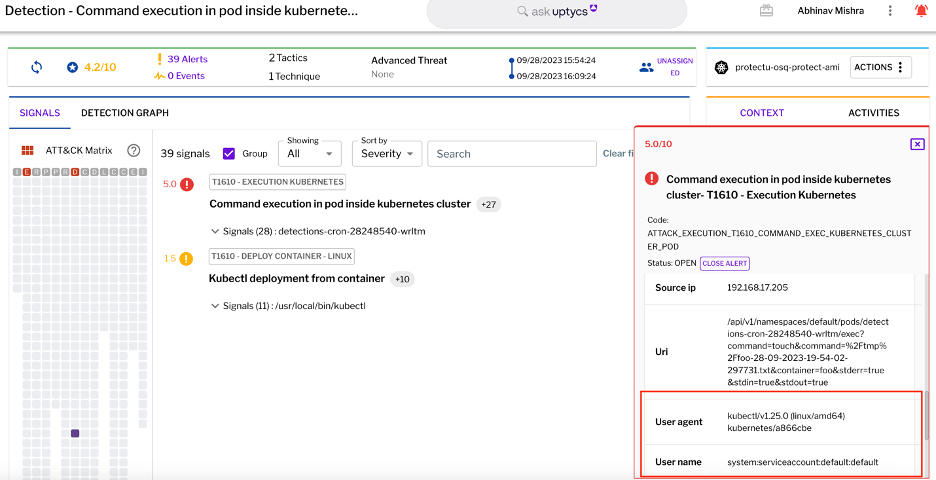
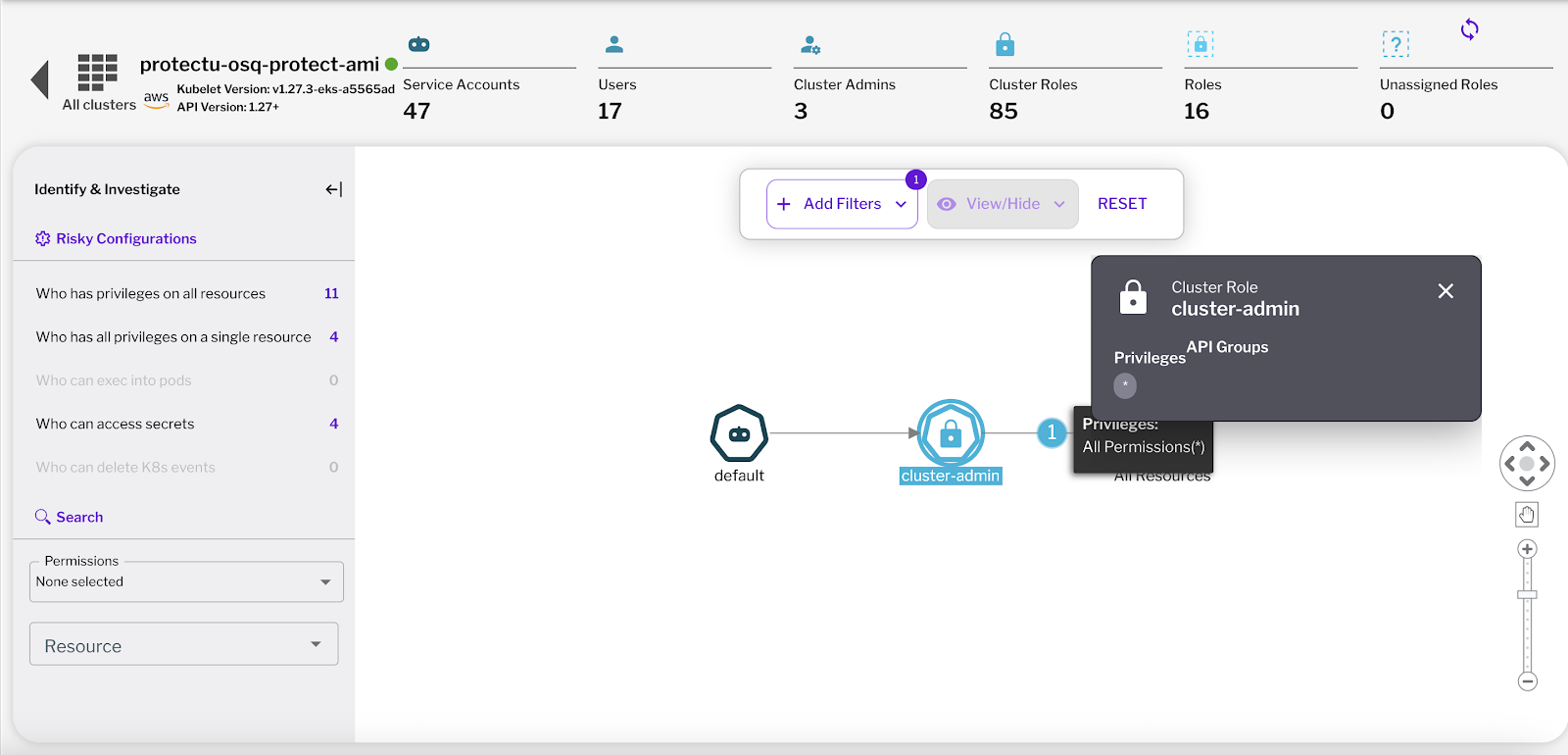


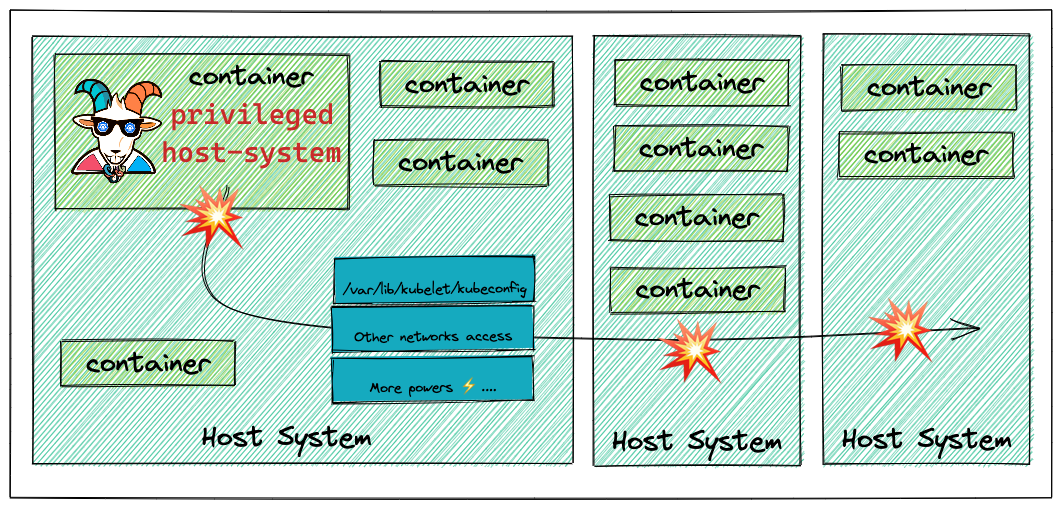 Figure 1 - Kubernetes container escape example
Figure 1 - Kubernetes container escape example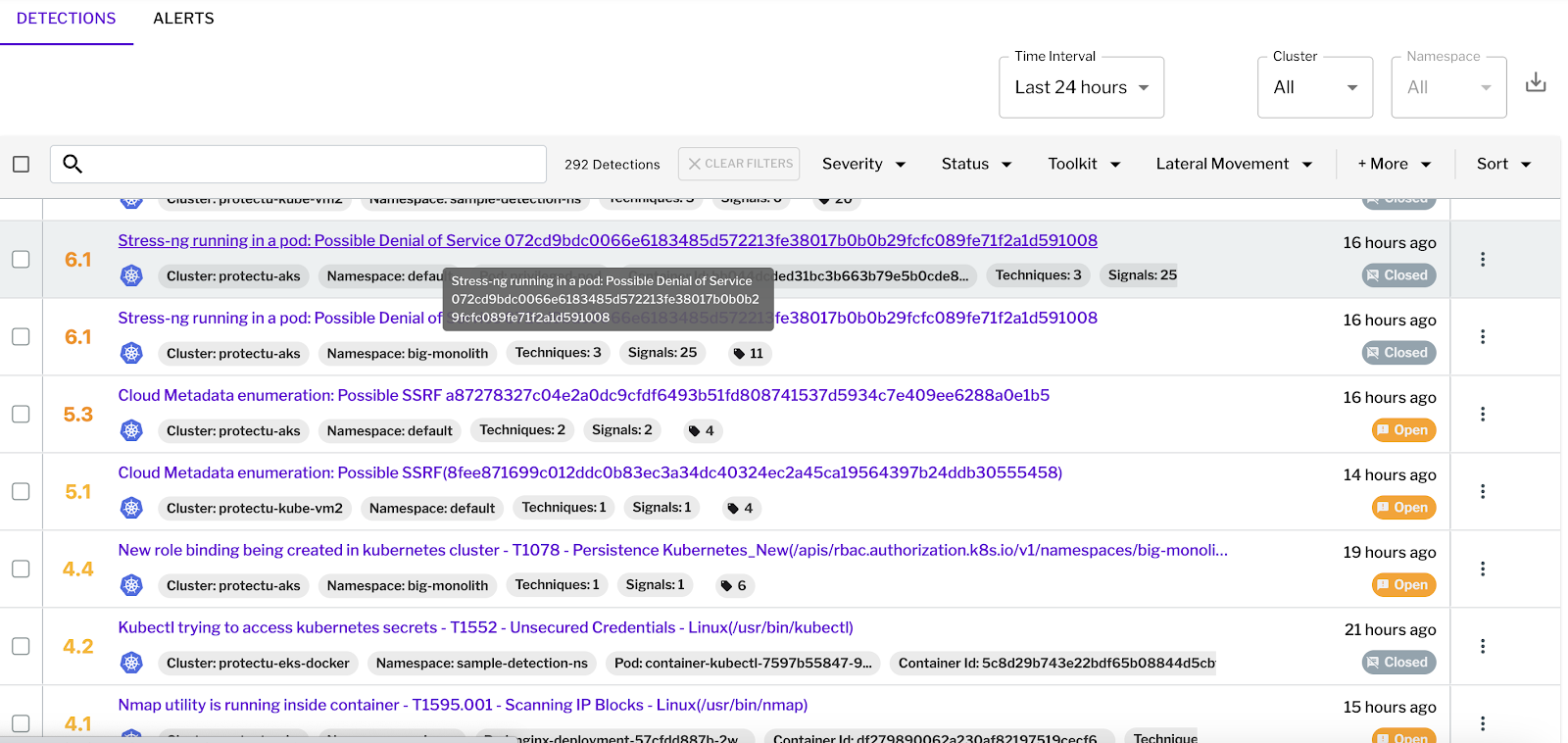
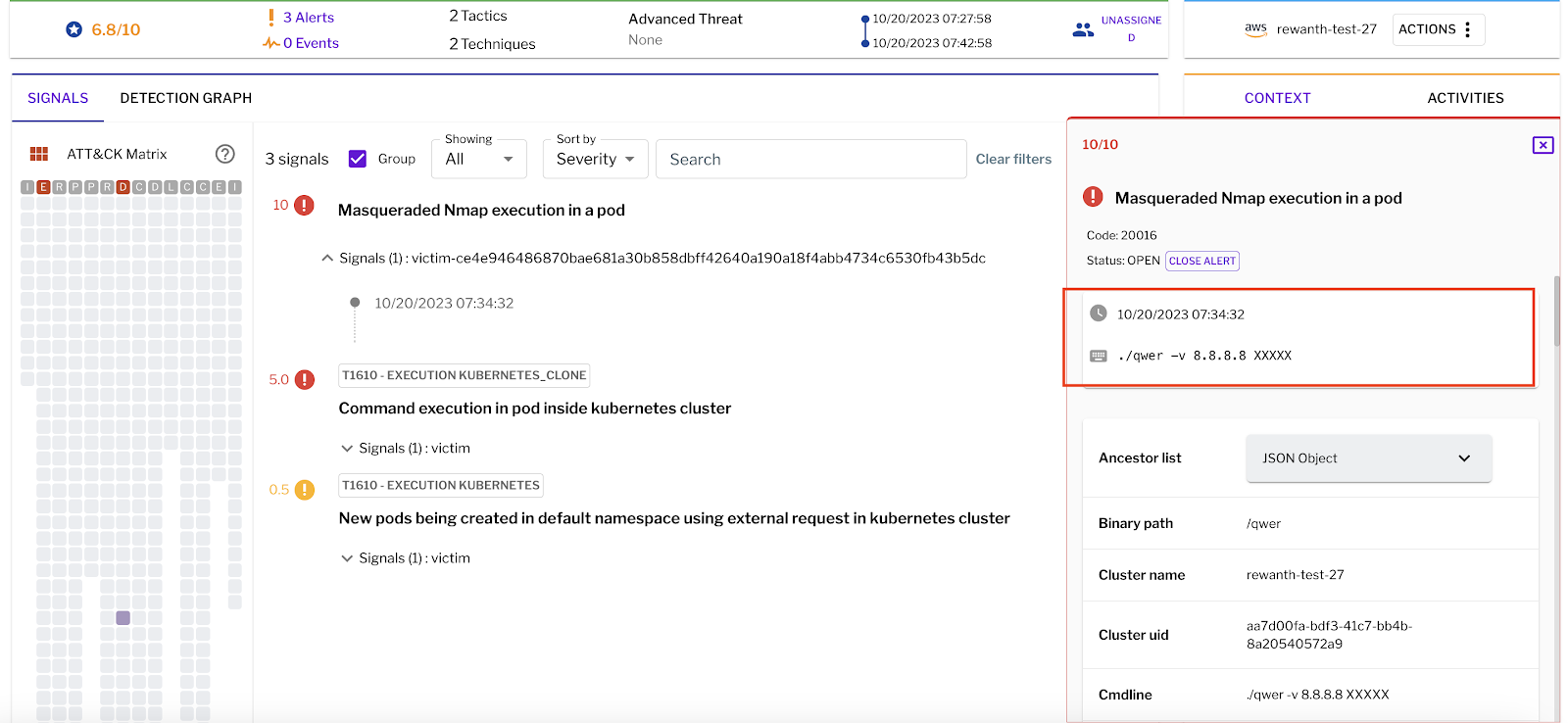 Figure 3 - Original nmap hiding behind /qwer
Figure 3 - Original nmap hiding behind /qwer





